
Beim maschinellen Lernen (ML) wird die Modellleistung sowohl von den Daten als auch von dem gewählten Lernalgorithmus beeinflusst. Im Allgemeinen würde man erwarten, dass je mehr (gute) Daten gesammelt werden, desto mehr Informationen extrahiert werden können und desto besser die Leistung des Modells wird. Es gibt jedoch einen Sättigungspunkt, an dem sich die Modellleistung auch mit zusätzlichen Daten nicht mehr verbessert. Diese Sättigung tritt ein, wenn die Größe der Daten einem Modell nicht helfen kann, die Annahmen des Lernalgorithmus zu übertreffen. Wenn z. B. ein lineares Modell verwendet wird, um Daten zu klassifizieren, in denen nichtlineare Beziehungen bestehen, wird eine perfekte Vorhersage nie erreicht, auch nicht mit einer großen Anzahl von Trainingsdaten.
Schauen wir uns ein Beispiel dafür an, wie sich die Größe der Trainingsdaten auf die Leistung von ML-Modellen auswirkt.
In der Online-Werbung ist es entscheidend, die Wahrscheinlichkeit abzuschätzen, mit der ein Benutzer auf eine Anzeige reagiert (entweder auf einen Klick oder eine Konversion). Diese Wahrscheinlichkeit zeigt das Interesse des Benutzers an einem Produkt oder einer Marke an und eine genaue Vorhersage verbessert sowohl das Benutzererlebnis als auch die Effektivität der Werbekampagne. Bei der Vorhersage der Click-Through-Rate (CTR) werden oft lineare Algorithmen wie die logistische Regression (LR) verwendet, und hier schauen wir uns an, wie die Datengröße die LR-Leistung beeinflusst. Wir werfen auch einen Blick auf die Ergebnisse für Factorization Machines (FM) - ein effizienter Algorithmus, um LR mit Cross-Features zu ergänzen. Hier konzentrieren wir uns auf die Auswirkung der Datengröße auf die Modellleistung und überlassen den Leistungsvergleich zwischen LR und FM einem separaten Beitrag.
Unsere Daten stammen von 5 Advertisern; die Tabelle unten zeigt die Anzahl der Einträge und die Anzahl der Features für jeden:
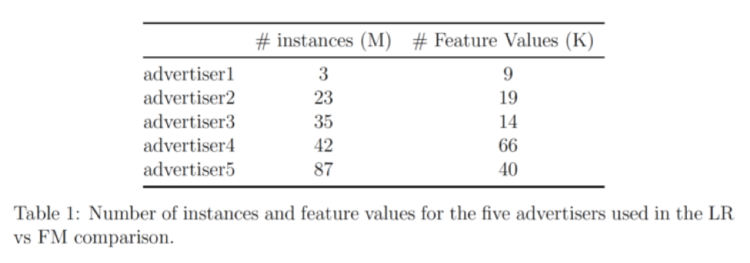
Dieser Datensatz wird vorverarbeitet und nach dem Zufallsprinzip in Datengruppen mit unterschiedlichen Größen unterteilt. Dann werden LR und FM separat auf jede Datengruppe angewendet, um Klassifizierungsmodelle zu generieren, die Modelle werden dann auf ausgelassenen Testdatensätzen mit AUC-Scores.
Die folgenden Abbildungen zeigen die Beziehung zwischen der Modellleistung und der Datengröße. Die horizontale Achse stellt den Stichprobenanteil dar, z. B. bedeutet 0,1, dass 10 % der Daten für das Training verwendet werden. Die vertikale Achse zeigt die Modellleistung (d. h. den AUC) an. Die AUC-Werte liegen bei den verschiedenen Werbetreibenden in unterschiedlichen Bereichen, was einen Vergleich erschwert. Um einen klareren Vergleich zu haben, skalieren wir den AUC für jeden Inserenten mit der folgenden Regel neu:
AUC_reskaliert = (AUC / AUC_avg - 1) * 100%
wobei AUC_avg der über alle Stichprobenfraktionen gemittelte AUC für diesen Advertiser ist.
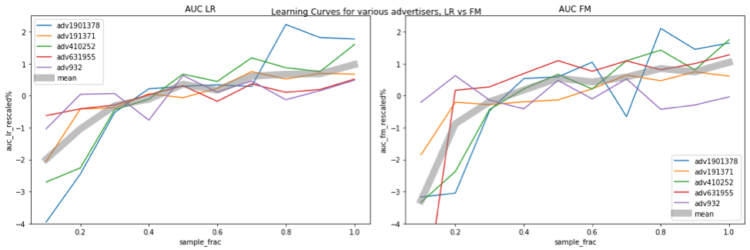
In der Darstellung sind die verschiedenen Werbetreibenden farblich gekennzeichnet, und die dicke graue Kurve stellt den durchschnittlichen neu skalierten AUC über alle 5 Werbetreibenden dar. Die Abbildungen links und rechts zeigen die Ergebnisse für LR bzw. FM. Es ist deutlich zu erkennen, dass die Modellleistung immer weiter ansteigt, wenn mehr Daten für das Training verwendet werden. Bei der im Test verwendeten Datenmenge erreichen weder LR noch FM die Sättigungswerte. Eine Sache, die erwähnenswert ist, ist, dass, wenn wir die Größe der Trainingsdaten erhöhen, auch der Merkmalsraum erweitert wird, daher steigt die Modellkomplexität, was es schwieriger macht, die Sättigung zu erreichen.
Es gibt auch einen interessanten Trend: Der AUC steigt um etwa 1 %, wenn sich die Datengröße fast verdoppelt. Diese Beziehung wird wahrscheinlich deutlicher, wenn wir ein lin-log-Diagramm erstellen, indem wir die x-Achse im logarithmischen Maßstab auftragen. Jetzt sehen wir eine gerade (eine Art, zumindest für LR) graue Linie, was bedeutet, dass, wenn wir x (Datengröße) exponentiell erhöhen, y (Leistung) um einen linearen Betrag steigt.
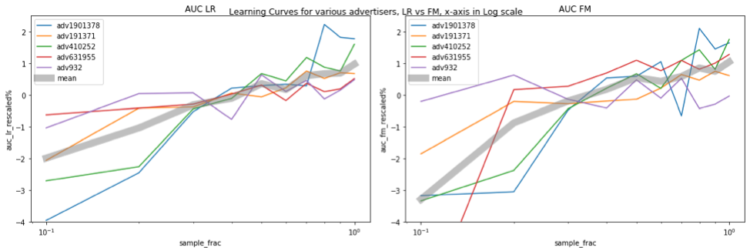
Zusammenfassend lässt sich sagen, dass in unserem Experiment der Sättigungspunkt mit zunehmender Datenmenge nie erreicht wurde. Wenn sich die Datenmenge verdoppelt, steigt die AUC um fast 1 %. Für industrielle Anwendungen wird eine 1%ige Steigerung der AUC oft als signifikante Verbesserung angesehen. Dies soll verdeutlichen, dass bei ausreichender Datenmenge die Erhöhung der Trainingsgröße eine unkomplizierte Möglichkeit zur Verbesserung der Modellleistung ist.



