
在机器学习(ML)中,模型的性能既受数据的影响,也受你所选择的学习算法的影响。一般来说,你会期望收集到的(好的)数据越多,你能提取的信息就越多,你的模型表现就越好。然而,存在着一个饱和点,即使有更多的数据,模型的性能也会停止提高。当数据的大小不能帮助一个模型超越学习算法的假设时,这种饱和就会发生。例如,当一个线性模型被用来对存在非线性关系的数据进行分类时,即使有大量的训练数据,也不会达到完美的预测。
让我们仔细看看训练数据大小如何影响ML模型性能的一个例子。
在网络广告中,估计用户对广告做出反应的概率是至关重要的(无论是点击还是转换)。这个概率表明用户对产品或品牌的兴趣,获得准确的预测可以改善用户体验和广告活动的有效性。在预测点击率(CTR)时,经常使用像逻辑回归(LR)这样的线性算法,这里我们将看看数据大小如何影响LR的性能。我们还看一下因数机(FM)的结果--这是一种为LR增加交叉特征的有效算法。在这里,我们集中讨论数据大小对模型性能的影响,而把LR和FM之间的性能比较留给另一篇文章。
我们的数据来自5个广告商;下表显示了每个广告商的条目数量和特征数量。
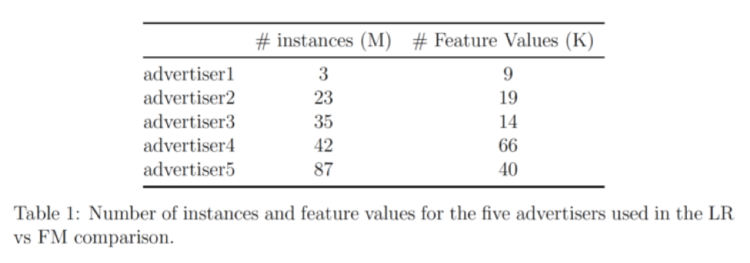
该数据集经过预处理并随机抽样为不同大小的数据组。然后将LR和FM分别应用于每个数据组,以生成分类模型,然后用以下方法对这些模型进行评估:1. AUC得分.
下面的数字显示了模型性能和数据大小之间的关系。 横轴表示采样比例,例如0.1意味着10%的数据用于训练。纵轴表示模型性能(即AUC)。不同的广告商的AUC值在不同的范围内,这使得比较变得困难。为了有一个更清晰的比较,我们对每个广告商的AUC进行重新划分,规则如下。
AUC_rescaled = (AUC / AUC_avg - 1) * 100%。
其中AUC_avg是该广告商所有抽样部分的平均AUC。
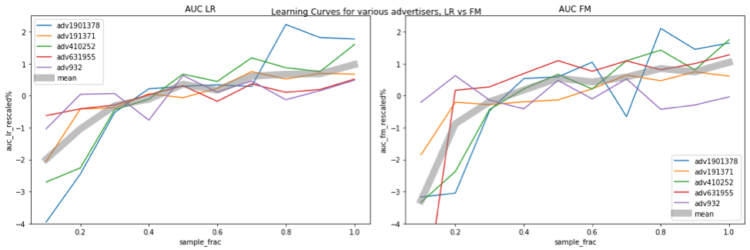
在图中,不同的广告商被用颜色编码,厚的灰色曲线代表了所有5个广告商的平均重新缩放的AUC。左边和右边的图分别显示了LR和FM的结果。很明显,当更多的数据用于训练时,模型的性能不断提高,而随着测试中使用的数据量的增加,LR和FM都没有达到饱和水平。有一点值得一提的是,当我们增加训练数据的大小时,特征空间也会扩大,因此,模型的复杂性也会增加,使其更难达到饱和。
还有一个有趣的趋势:当数据量几乎翻倍时,AUC增加了大约1%。如果我们把X轴按对数比例绘制成线对数图,这种关系可能会更清楚,现在我们看到一条笔直的(有点像,至少对LR来说)灰线,这意味着当我们按指数增加X(数据大小)时,Y(性能)会以线性数量增加。
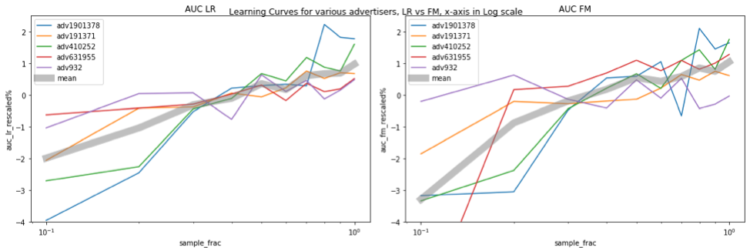
总之,在我们的实验中,随着数据量的增加,饱和点从未被满足。当数据量增加一倍时,AUC几乎增加了1%。 对于工业应用来说,AUC增加1%通常被认为是一个重大的改进。这是为了说明,当有足够的数据时,增加训练规模是提高模型性能的一个直接的方法。



