
A lot of digital display advertising these days involves predicting the probability of a click or some other user action, like a purchase. The most common machine learning algorithm for making click-through rate (CTR) predictions is Logistic Regression (LR).
During real time bidding (RTB) for a particular ad space on a web page, the features, such as browser, region, device type, etc., are used by an LR model to calculate click probability. This probability influences whether a bid will be made and how high that bid will be. Incorrect predictions can result in high cost per click, which translates to low margins and unhappy clients.
Logistic regression is fast, which is important in RTB, and the results are easy to interpret. One disadvantage of LR is that it is a linear model, so it underperforms when there are multiple or non-linear decision boundaries. For example, consider a case where data consist of only two features with two values each as shown in Figure 1. It is impossible to draw a straight line in this scenario such that the positives are on one side of it and the negatives on the other. One way to work around this linearity constraint is to convert the feature vectors into a higher dimensional space by introducing feature interactions. A third feature called “Hour-Domain” could be added. This makes the feature vector space three dimensional as shown in Figure 2.

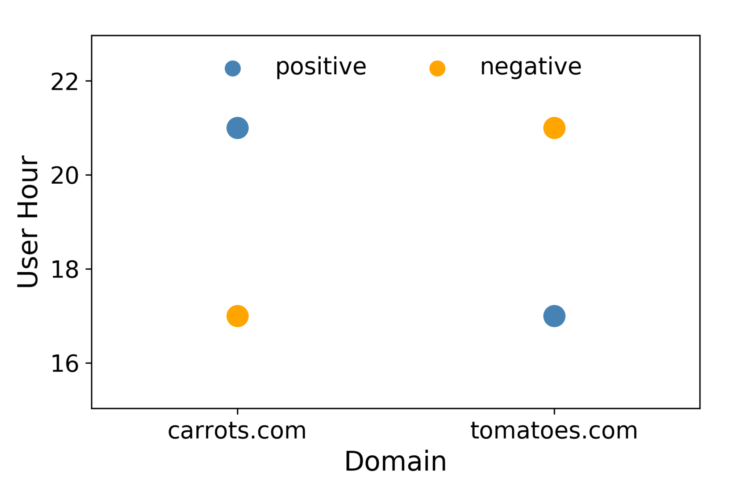
Figure 1: No good linear decision boundary exists for this scenario.
A plane can now be drawn to separate the positives from the negatives. So with a bit of feature engineering we can make LR learn relationships between feature pairs. However, that comes with a price. Adding feature interactions increases a model’s complexity to O(n2), where n is the total number of values in a dataset.
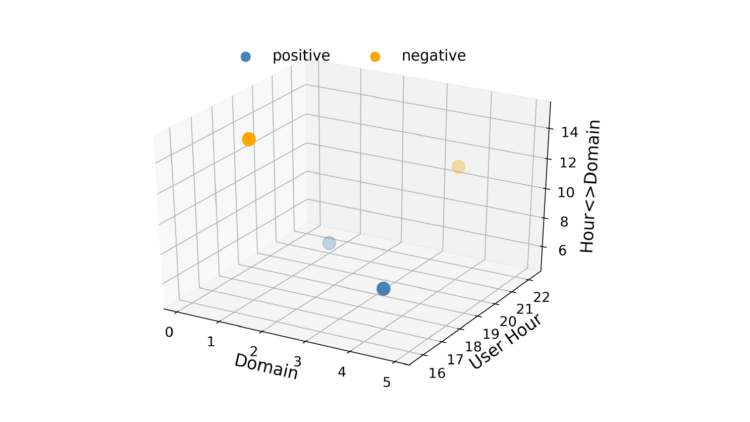
This is impractical for CTR predictions where a model could have thousands of values. Also, if a value pair doesn’t exist in a dataset, Logistic Regression won’t be able to learn its interaction strength. Factorization Machines (FM) [1, 2] tackle both of these problems.
What Are Factorization Machines?
To answer this question it is helpful to know about matrix factorization, also called matrix decomposition. It is simply decomposing a matrix into a product of several other matrices. In other words, matrix factorization is simply a mathematical tool to play around with matrices to find out something hidden under the data. Principal Component Analysis (PCA) is an example of a matrix factorization model.
Usually it is not trivial to apply a factorization approach to a new problem. Factorization machines make it a lot easier because they can achieve similar results as other factorization models just by using feature engineering [3]. Let’s take a look at the cost function used in linear CTR prediction modeling.
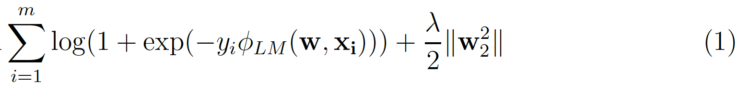

m is the number of (xᵢ, yᵢ) instances in a dataset, where yᵢ is the click/no-click label and xᵢ is the n-dimensional feature vector. The second term is the L₂ regularization term where ƛ is the regularization strength. For Logistic Regression

Adding interactions introduces another term.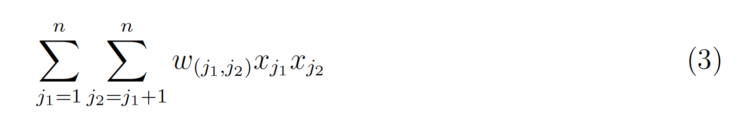

w(j₁ ;j₂) is the LR weight for the interaction, so a weight is learned for every single interaction pair. The trick of Factorization Machines is to learn a k-dimensional latent vector for each feature, where k is a user specified parameter. The interaction effect can then be simply calculated by taking the inner product of the two vectors.
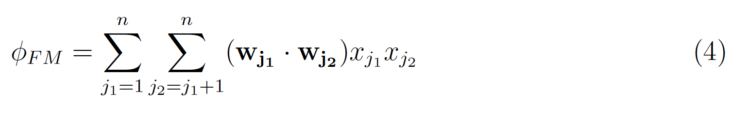

which can be rewritten as
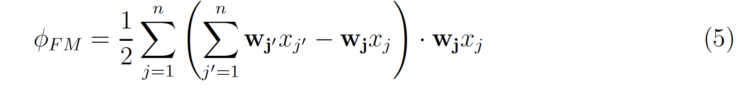

The complexity of the above equation is only O(nk), where n is the average number of non-zero values per instance.
Logistic Regression vs Factorization Machines
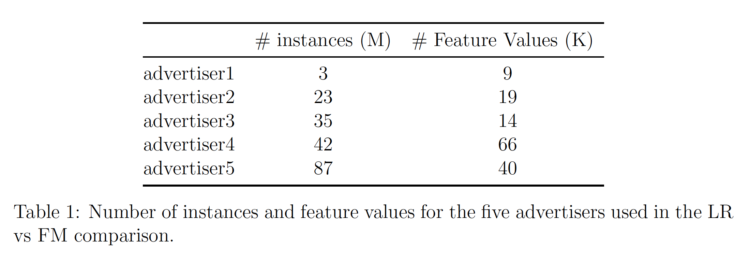
We used AWS Sagemaker’s implementation of Factorization Machines to test FM on our data. Information about the data for the five different advertisers analyzed is listed in Table 1.

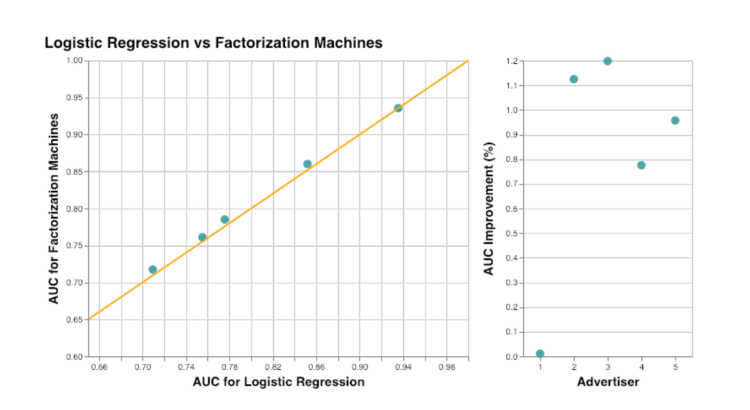
AUC metric was used to compare Factorization Machines to Logistic Regression. The results are summarized in Figure 3. There was no improvement for one of the advertisers, but its AUC was already greater than 0.9. On average (if the outlier advertiser is excluded), using Factorization Machines improves AUC by about 1%. As expected, we see that adding information about feature interactions improves click predictions. And by using FMs instead of manually adding all feature combinations to Logistic Regression, the complexity of the model can be decreased.
We report on training process of FM models using AWS Sagemaker in another post.

Guest authored by:
Inga Silkworth, Head of Data Science at Virtusize, Japan



