
现在很多数字显示广告都涉及到预测点击或其他用户行为的概率,如购买。用于预测点击率(CTR)的最常见的机器学习算法是逻辑回归(LR)。
在实时竞价(RTB)的过程中,网页上的特定广告空间的特征,如浏览器、地区、设备类型等,被LR模型用来计算点击概率。这个概率影响到是否会出价以及出价的高低。不正确的预测会导致每次点击的高成本,从而转化为低利润和不快乐的客户。
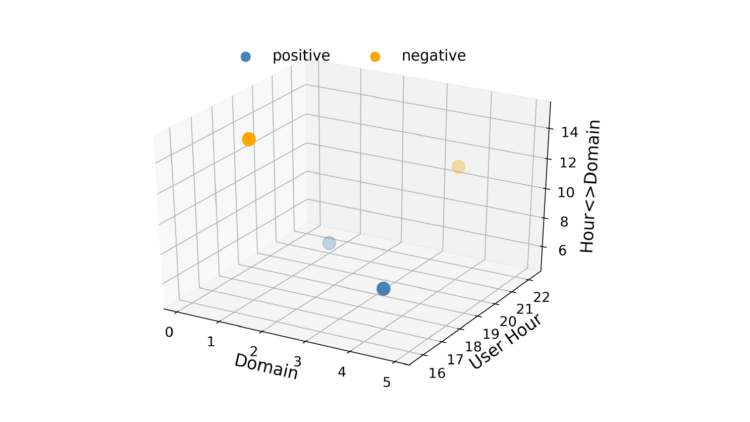
逻辑回归的速度很快,这在RTB中很重要,而且结果很容易解释。LR的一个缺点是它是一个线性模型,所以当存在多个或非线性的决策边界时,它的表现不佳。例如,考虑一种情况,即数据只由两个特征组成,每个特征有两个值,如图1所示。在这种情况下,不可能画一条直线,使正数在它的一边,负数在另一边。绕过这个线性约束的一个方法是通过引入特征的相互作用将特征向量转换成一个更高的维度空间。可以添加第三个称为 "小时域 "的特征。这使得特征向量空间成为三维空间,如图2所示。

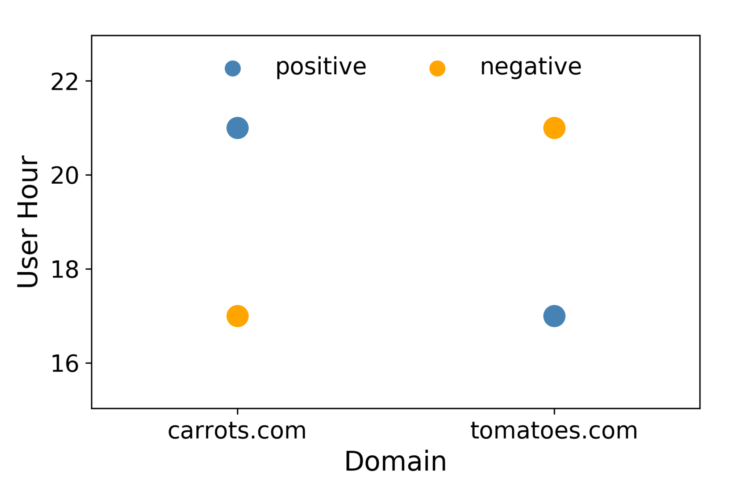
图1:这种情况下不存在良好的线性决策边界。
现在可以画出一个平面,将正片与负片分开。因此,通过一些特征工程,我们可以使LR学习特征对之间的关系。然而,这也是有代价的。增加特征的相互作用会使模型的复杂度增加到O(n2),其中n是数据集中数值的总数。
这对CTR预测来说是不切实际的,因为一个模型可能有成千上万的值。此外,如果一个数据集中不存在一个值对,逻辑回归将无法学习其交互强度。因式分解机(FM)[1,2]可以解决这两个问题。
什么是因式分解机?
要回答这个问题,了解矩阵因式分解是有帮助的,也叫矩阵分解。它只是将一个矩阵分解为其他几个矩阵的乘积。换句话说,矩阵因式分解只是一种数学工具,用来玩弄矩阵以找出隐藏在数据下的东西。主成分分析(PCA)是矩阵分解模型的一个例子。
通常情况下,将一个因式分解方法应用于一个新的问题并非易事。因式分解机使它变得容易得多,因为它们仅仅通过使用特征工程就可以达到与其他因式分解模型相似的结果[3]。让我们来看看线性CTR预测建模中使用的成本函数。
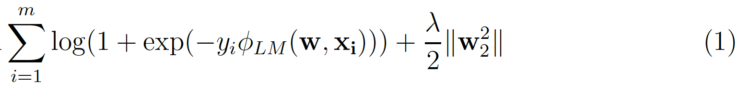

m 是( )的数量。xᵢ, yᵢ)实例的数据集,其中yᵢ是点击/不点击的标签和 xᵢ 是指 n的特征向量。第二个项是L₂正则化项,其中ƛ 是正则化强度。对于Logistic回归

增加互动就会引入另一个术语。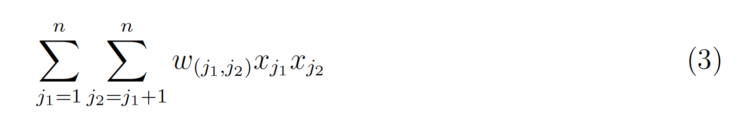

w(j₁ ;j₂)是交互作用的LR权重,所以每一个交互作用对都要学习一个权重。因式分解机的技巧是学习一个 k维的潜在向量,其中k是用户指定的参数。然后,可以通过取两个向量的内积来简单地计算交互效应。
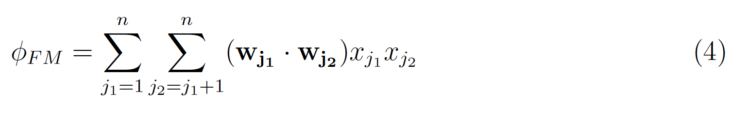

可以改写为
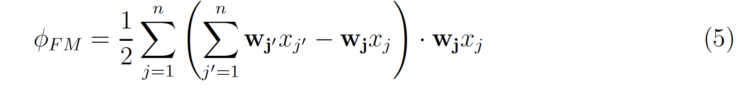

上述方程的复杂性仅为 O(nk),其中n是每个实例的非零值的平均数.
Logistic回归与因子化机器
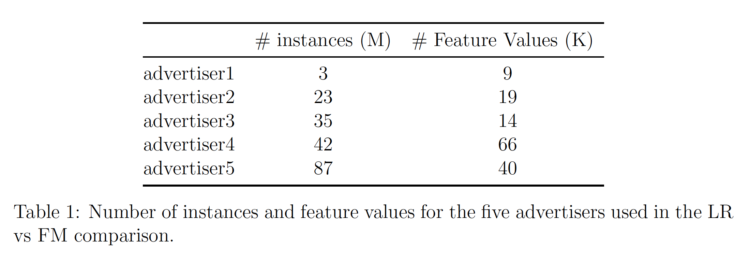
我们使用AWS Sagemaker的因子化机器的实现,在我们的数据上测试FM。表1中列出了所分析的五个不同广告商的数据信息。

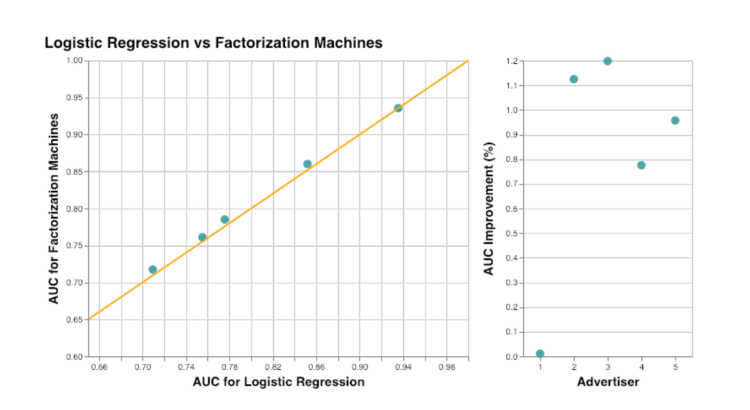
AUC指标被用来比较因子化机器和逻辑回归。结果总结在图3中。其中一个广告商没有改善,但其AUC已经大于0.9。平均来说(如果排除了那个离群的广告商),使用因子化机器可以提高AUC大约1%。正如预期的那样,我们看到添加关于特征交互的信息可以改善点击预测。而通过使用调频而不是手动添加所有特征组合到逻辑回归中,可以降低模型的复杂性。
我们在另一篇文章中报告了使用AWS Sagemaker训练FM模型的过程。

特邀作者:。
Inga Silkworth,日本Virtusize公司的数据科学主管。



